This guide outlines a fully automated workflow for building a RAG (Retrieval-Augmented Generation) knowledge base. Simply input a website’s sitemap URL, click “Execute”, and let the system handle the rest: automatic web scraping -> AI-powered cleaning and structuring -> saving to local Markdown files.
The final result? The essential content from your target website is transformed into a neat, uniform set of knowledge base files on your local machine!
🛠️ Step 1: Prepare Our “Swiss Army Knife” Toolkit
We’ll use Docker to simplify the installation of these powerful tools.
1. n8n: The Automation Brain
n8n is the core of our workflow—an open-source, visual workflow automation tool. Think of it as a super-powered “if…then…” system.
- Website: https://n8n.io/
- Installation (via Docker):
# Stop and remove any existing container
docker stop n8n
docker rm n8n
# Create a local directory for persistent data (adjust the path for your user)
mkdir -p ~/opt/n8n_data
# Pull the latest image
docker pull n8nio/n8n:latest
# Run the n8n container
docker run -d --restart unless-stopped \
--name n8n \
-e GENERIC_TIMEZONE="Your/Timezone" \ # e.g., Asia/Shanghai
-e N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true \
-e N8N_RUNNERS_ENABLED=true \
-p 5678:5678 \
-e N8N_DEFAULT_LOCALE=en \ # Or your preferred locale
-e N8N_SECURE_COOKIE=false \
-v n8n_data:/home/node/.n8n \ # Named volume for n8n core data
-v /Users/your_username/opt/n8n_data:/data \ # Map local dir for output files (CRITICAL)
n8nio/n8nKey Point: The -v ~/opt/n8n_data:/data flag maps your local directory to the container’s /data directory, allowing you to access the generated Markdown files easily.
2. Crawl4ai: The Web Scraping Expert
A crawler designed for AI that elegantly converts web pages into clean Markdown format—perfect for preparing knowledge base data.
- GitHub: https://github.com/unclecode/crawl4ai
- Installation (via Docker):
docker run -d \
-p 11235:11235 \
--name crawl4ai \
-e CRAWL4AI_API_TOKEN=datascience \ # Set the access token
-v ./crawl4ai_data:/data \
--restart unless-stopped \
unclecode/crawl4ai:latestNote: Remember the API token (datascience), as it will be used later in n8n.
Robots.txt: Remember to respect the website’s robots.txt file.
3. Ollama & BGE-M3: The Local LLM Home
Ollama lets you run large language models locally. We’ll use it to run the bge-m3 model, a powerful embedding model crucial for creating vector embeddings for RAG retrieval.
- Website: https://ollama.com/
- Installation (via Docker):
# CPU mode
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaPulling the Model:
Since Ollama runs in a container, execute this command to pull the model:
docker exec -it ollama ollama pull bge-m3BGE-M3 Note: This is an embedding model from BAAI, known for its versatility (dense, multi-vector, and sparse retrieval), multilingual support (100+ languages), and ability to handle long documents.
4. Cherry Studio (Optional – For Using the Knowledge Base)
Cherry Studio is an all-in-one AI assistant platform featuring multi-model chat, knowledge base management, and more. It’s an excellent tool for querying and utilizing the local knowledge base you create.
- Website: https://www.cherry-ai.com/
- Download: https://docs.cherry-ai.com/cherry-studio/download
5. Docker Container IP Address Cheat Sheet
Use these commands to find container IPs if needed for network configuration (often localhost or container name suffices in Docker).
Single Container IP:
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' <container-name>All Container IPs:
docker inspect -f '{{.Name}} - {{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' $(docker ps -aq)🧠 Step 2: Build the Automated Workflow
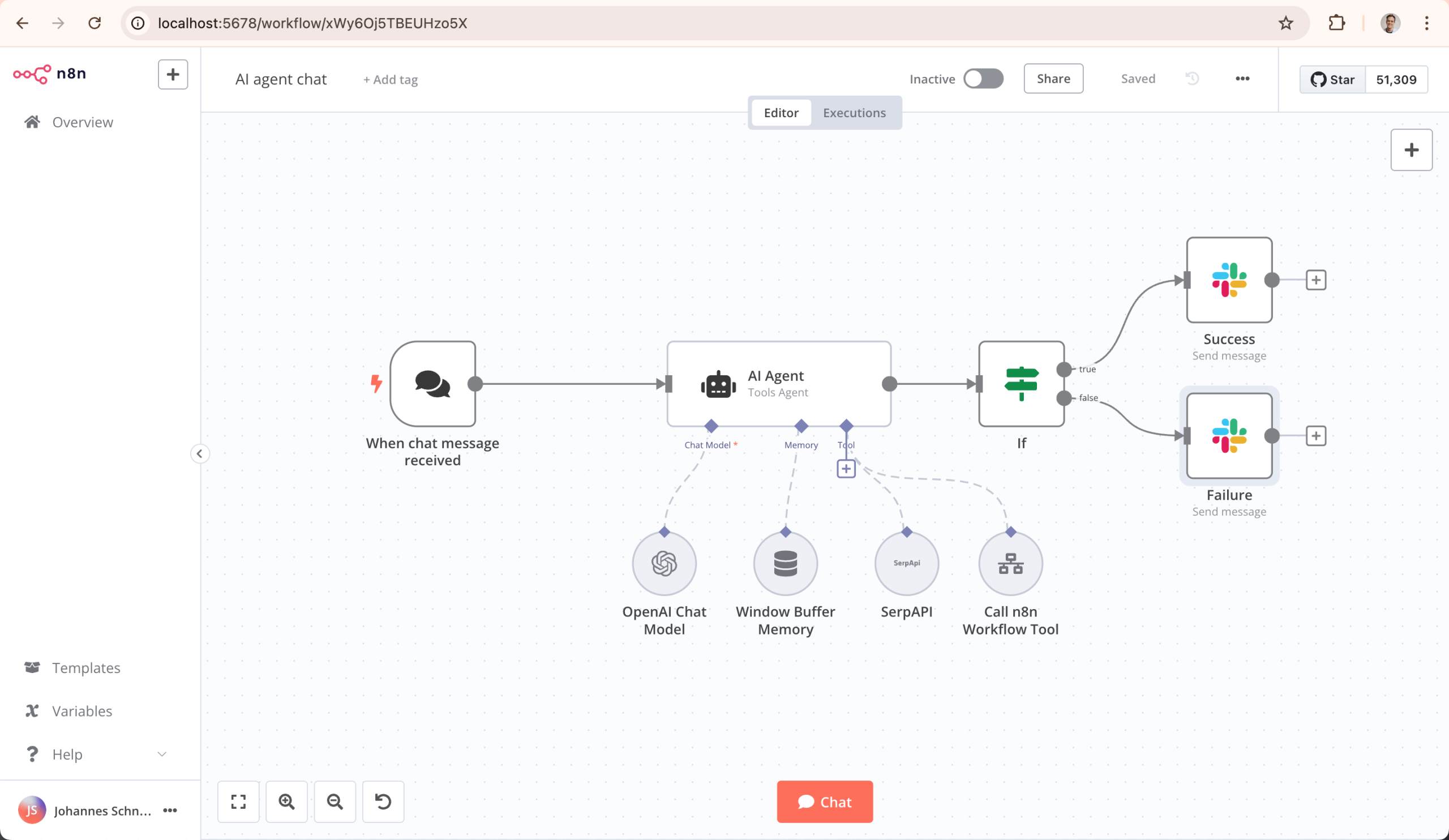
Here’s the logic of the complete workflow. Build it from left to right in the n8n editor (accessible at http://localhost:5678).
Nodes 1-4: Fetch & Parse the Sitemap
- Manual Trigger / Webhook: The starting point. This is where you will input the sitemap URL (e.g.,
https://docs.n8n.io/sitemap.xml). - HTTP Request Node (Get Sitemap): Sends a request to the sitemap URL to fetch the list of all public pages (in XML format).
- XML Node (Parse Sitemap): Parses the retrieved XML data into a JSON structure that n8n can work with.
- SplitOut Node (Split URLs): Iterates over the list of URLs found in the sitemap, splitting them into individual items for processing.
Nodes 5-7: Loop & Scrape Page Content
- Limit Node (Optional – For Testing): Set a limit (e.g., 15 pages) to test the workflow before processing the entire sitemap.
- Loop Over Items / Iterator Node: The “engine” of the workflow. It takes each page URL from the previous step and processes it through the subsequent nodes in the loop.
- HTTP Request Node (Call Crawl4ai): The core of the scraping loop.
- URL:
http://localhost:11235/md(orhttp://crawl4ai:11235/mdif using Docker Compose) - Method:
POST - Body (JSON):
{"url": "{{ $json['loc'] }}"}- Explanation: The
{{...}}expression dynamically inserts the current page’s URL from the loop into the request.
- Explanation: The
- Headers / Authentication:
- Add an
Authorizationheader. - Value:
Bearer datascience(matching theCRAWL4AI_API_TOKENset earlier).
- Add an
- URL:
Nodes 8-10: AI Processing & Structuring
- IF Node (Check Success): Checks if Crawl4ai successfully returned content. Only proceeds if true.
- AI Agent / Code Node (Prompt Processing): This is where the “magic” happens. This node sends a precise instruction (prompt) to an LLM (configured elsewhere in n8n, e.g., using DeepSeek’s API or a local model via Ollama) to act as an information structuring expert.
- Prompt Core Idea:
- Role: You are an expert in information structuring and knowledge base development.
- Task:
- Parse the scraped Markdown content.
- Structure it logically with clear headings and hierarchy.
- Create relevant FAQs based on the content.
- Improve readability and formatting.
- Optional: Translate the content to a specific language (e.g., Chinese).
- Output only the cleaned, structured core content without extra explanations.
- Prompt Core Idea:
- LLM Configuration Node (e.g., DeepSeek Chat Model): This node (often linked to the AI Agent) is configured with the API details for the chosen LLM provider.
Nodes 11-13: Save the Results
- IF Node (Check AI Output): Ensures the AI node produced output before saving.
- Convert to File / Set Node: Prepares the AI’s text output to be saved as a file.
- Write Binary File Node (Write to Disk): The final step! Saves the processed content to the mounted local directory.
- File Name: Use an expression like:
/data/{{ $('AI Agent').item.json.output.split('\n')[0].replace(/#|\s|\\/g, '') }}.md - Explanation: This creates a filename based on the first line of the AI’s output (often the main title), removes hashes (
#), spaces, and backslashes (\), and saves it with a.mdextension in the/datafolder (which maps to your local~/opt/n8n_data).
- File Name: Use an expression like:
Click “Execute Workflow” and watch the automation happen!
Note: For the complete n8n documentation, you can always clone the repo: https://github.com/n8n-io/n8n-docs
🚀 Step 3: Explore Your New Knowledge Base
Once execution is complete, open your local ~/opt/n8n_data directory. You will find all the scraped web pages, processed and neatly structured by the AI, saved as individual Markdown files.
You can now use any Markdown-compatible knowledge base software (like Obsidian, Logseq, or Cherry Studio) to manage, search, and utilize this powerful, fully local knowledge base!
Summary
This workflow combines the automation power of n8n, the precise scraping of Crawl4ai, the intelligent processing of LLMs, and the deployment simplicity of Docker to create an efficient “knowledge production line.”
Key Advantages:
- Fully Automated: Configure once, run anytime.
- Highly Customizable: Scrape any website and tailor the AI’s prompt to your specific needs.
- Local & Private: All data is processed and stored on your local machine, ensuring security and control.




