Deploying DeepSeek on Linux Using Ollama
1. What is Ollama?
Ollama is a tool for running large language models (LLMs) locally. It allows you to directly execute AI models on your own computer without needing to connect to cloud servers.
In simple terms: Ollama lets you effortlessly use major large language models like ChatGPT, Llama, Mistral, Gemma, and DeepSeek on your local machine, just as you would run ordinary software.
Core Features of Ollama
- Local Execution
No internet connection or privacy concerns—All computations are performed on your computer. - Support for Multiple Open-Source Models
Capable of running diverse large models such as Llama 3, Mistral, Gemma, and Code Llama. - Ease of Installation and Use
Download and run AI models with just a few commands. - Lightweight Optimization
Compatible with Mac (Apple Silicon), Linux, and Windows. Supports GPU acceleration to speed up model performance. - Offline Inference
Ideal for users who prefer not to rely on OpenAI APIs or other cloud-based AI services.
Ollama Official Website: https://ollama.ai/
Linux System Installation
One-Command Installation
Install Ollama using the following command:
curl -fsSL https://ollama.com/install.sh | sh
After installation, verify success with:
ollama --versiong
Docker Installation
Pull the Ollama Docker Image
docker pull ollama/ollama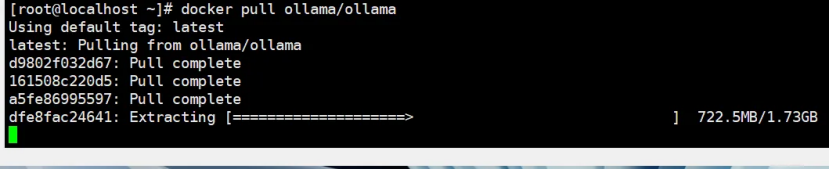
Start the Ollama Container
docker run -itd -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Parameter Explanations:
-v ollama:/root/.ollama: Mounts a Docker volume namedollamato the container’s/root/.ollamadirectory, ensuring data persistence (e.g., downloaded models will not be lost).-p 11434:11434: Maps port 11434 from the host machine to the container, allowing access to the Ollama service viahttp://localhost:11434on the host.--name ollama: Specifies the container name asollamafor easier management and startup.ollama/ollama: Uses the official Ollama Docker image.
Starting with GPU Support
To run Ollama using a GPU, use this command instead:
docker run -itd --name ollama --gpus=all -v ollama:/root/.ollama -p 11434:11434 ollama/ollama
Verify the Container
Check if the container is running:
docker ps
Access the container’s terminal:
docker exec -it ollama /bin/bash
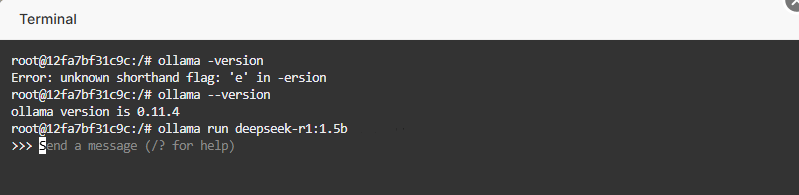
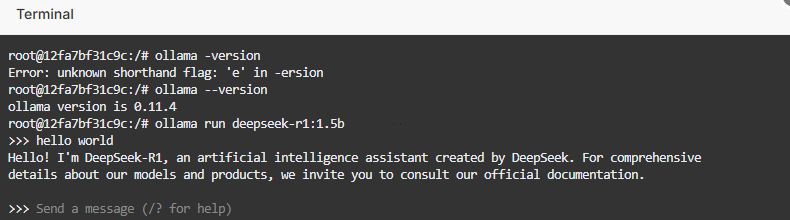
Running DeepSeek-R1
Execute the following command to launch the DeepSeek-R1 model:
ollama run deepseek-r1:1.5b
Wait for the model to download and initialize. A successful startup will be indicated by the following prompt:
Related articles