Exploratory Data Analysis (EDA) is a crucial part of data science model development and dataset investigation. When presented with a new dataset, a significant amount of time is often spent on EDA to uncover the underlying information within the data. Automated EDA Python packages can perform EDA with just a few lines of Python code.
This article compiles 10 Python packages that can automate EDA and generate insights about your data. Let’s explore their features and how much they can help us automate our EDA needs.
- DTale
- Pandas-profiling
- sweetviz
- autoviz
- dataprep
- KLib
- dabl
- speedML
- datatile
- edaviz
1. D-Tale
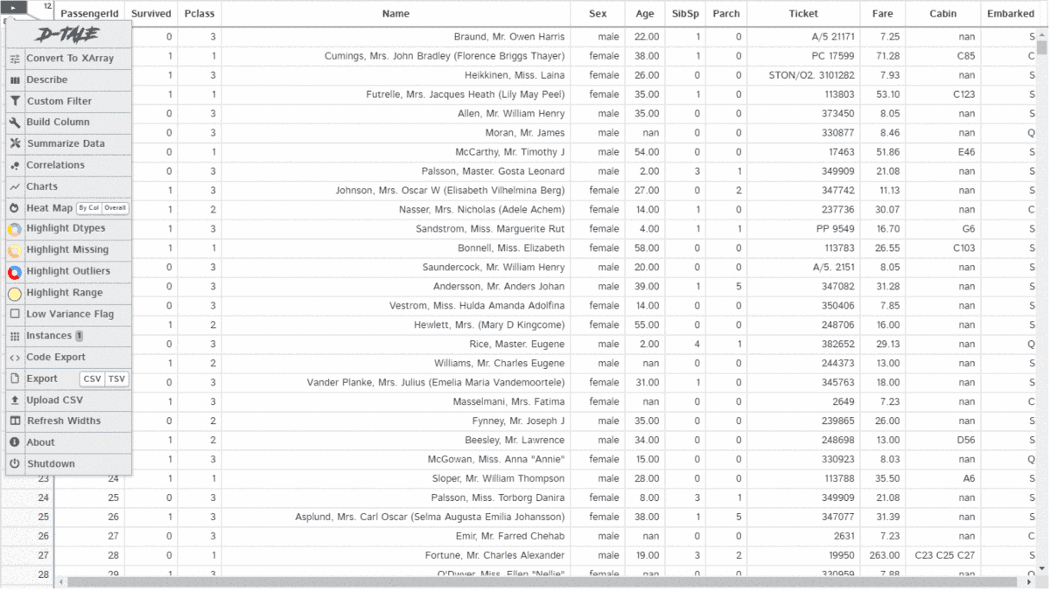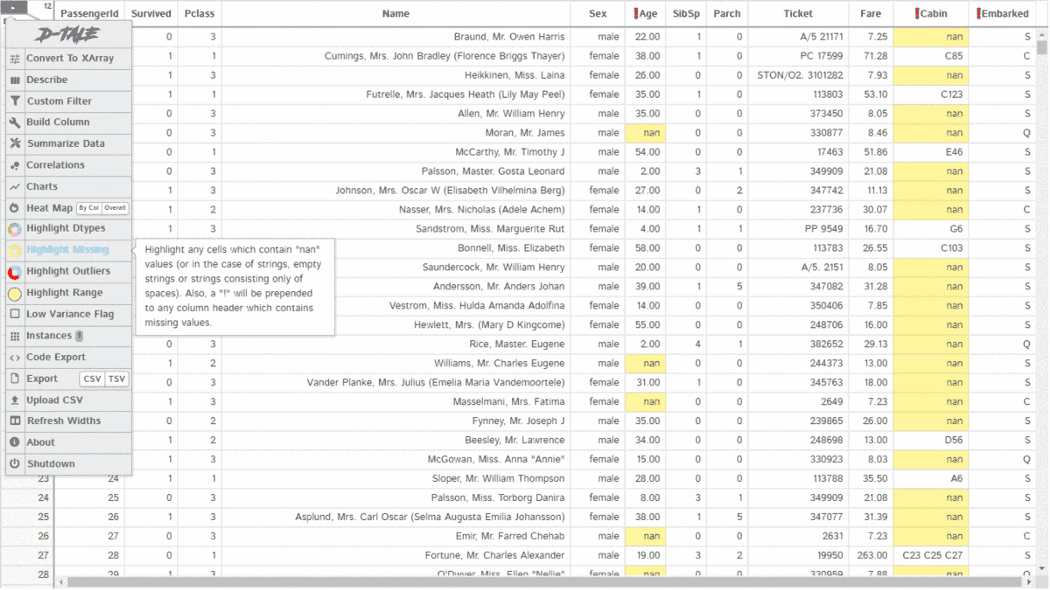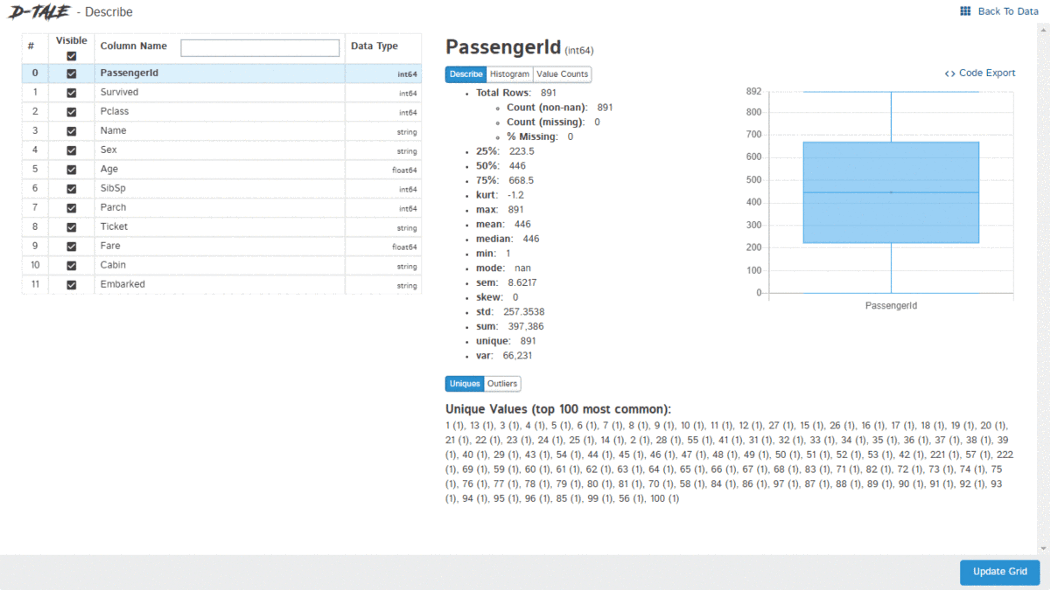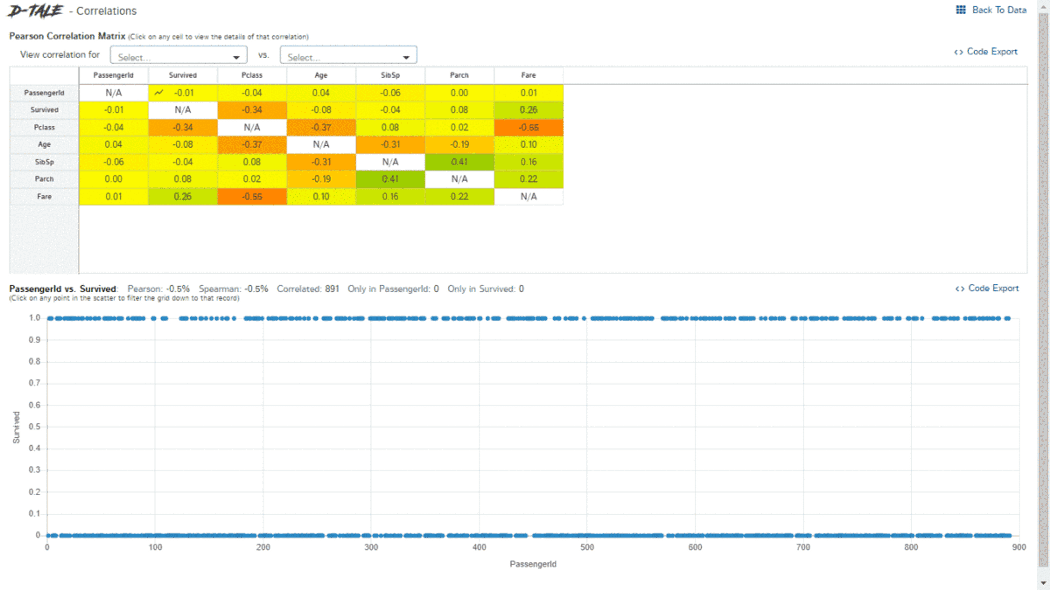
D-Tale uses Flask as a backend and React as a frontend, seamlessly integrating with IPython notebooks and the terminal. D-Tale supports Pandas DataFrame, Series, MultiIndex, DatetimeIndex, and RangeIndex.
python
import dtale
import pandas as pd
dtale.show(pd.read_csv("titanic.csv"))
The D-Tale library can generate a report with a single line of code. This report includes an overall summary of the dataset, correlations, charts, and heatmaps, and highlights missing values, among other things. D-Tale also allows for analysis of each chart within the report. As seen in the screenshot above, the charts are interactive.
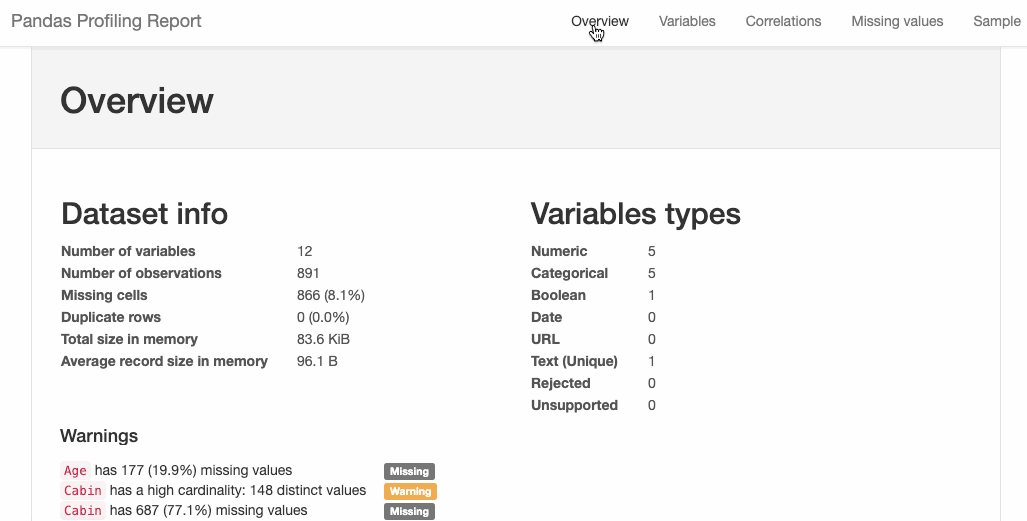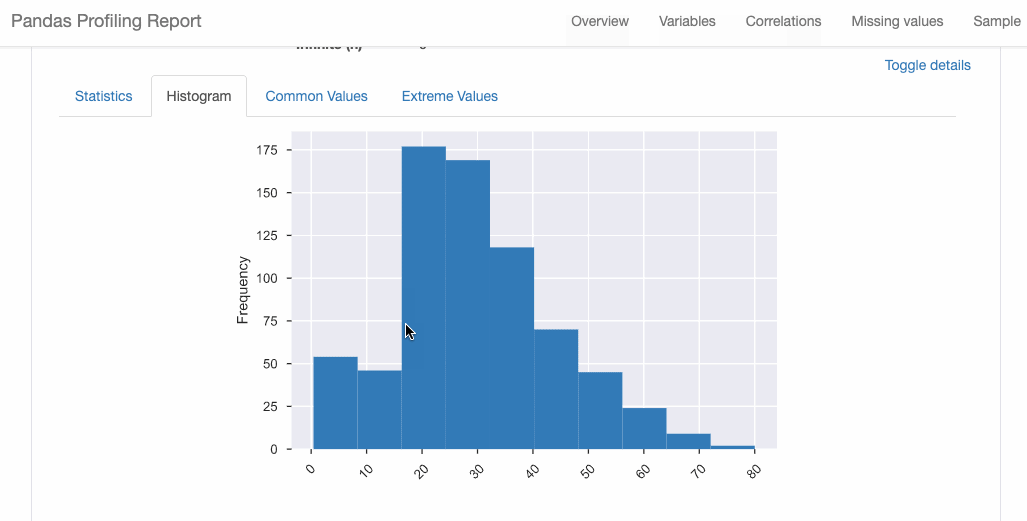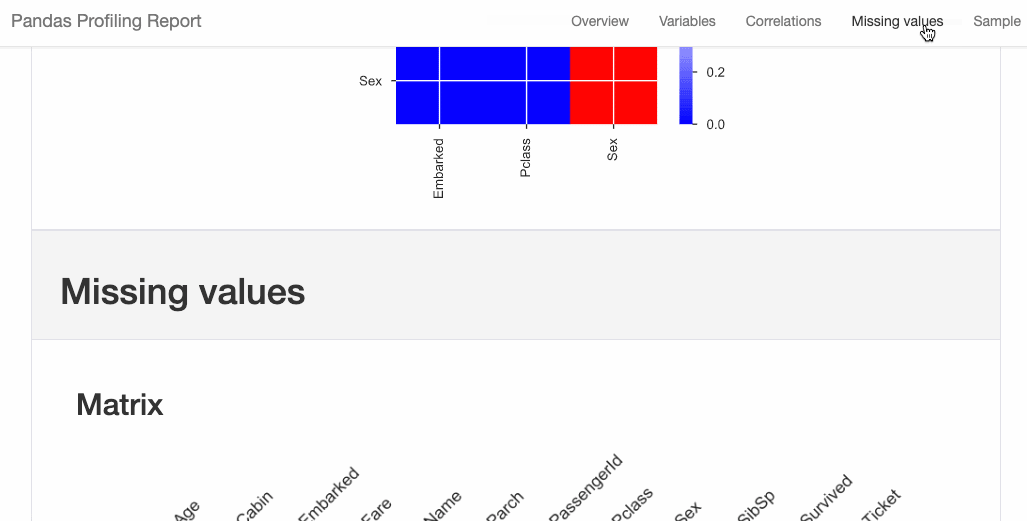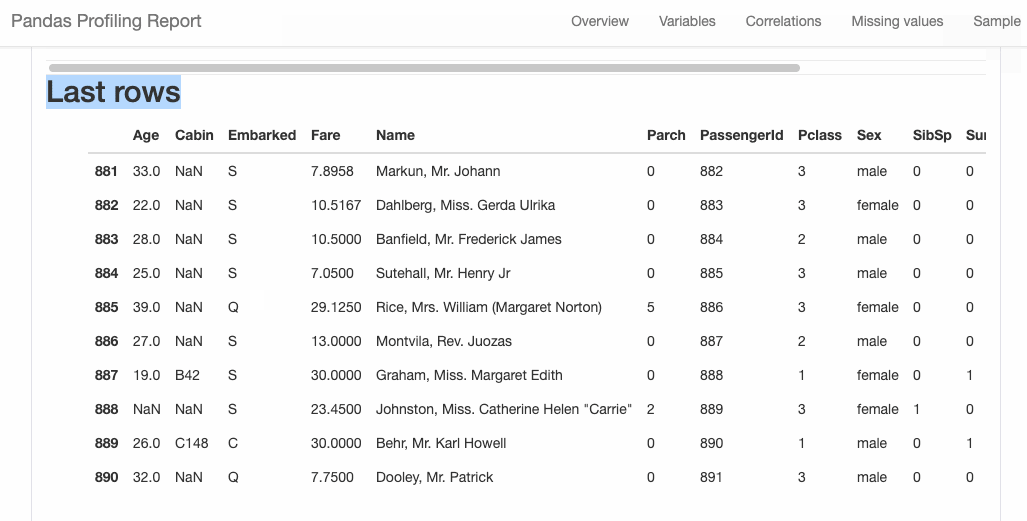
2. Pandas-Profiling
Pandas-Profiling generates profile reports from a Pandas DataFrame. The pandas-profiling package extends the Pandas DataFrame with the df.profile_report() method and works very well on large datasets, creating reports in seconds.
python
#Install the below libaries before importing
import pandas as pd
from pandas_profiling import ProfileReport
#EDA using pandas-profiling
profile = ProfileReport(pd.read_csv('titanic.csv'), explorative=True)
#Saving results to a HTML file
profile.to_file("output.html")
3. Sweetviz
Sweetviz is an open-source Python library that generates beautiful visualizations and launches EDA as an HTML application with just two lines of Python code. The Sweetviz package is built around quickly visualizing target values and comparing datasets.

python
import pandas as pd
import sweetviz as sv
#EDA using Sweetviz
sweet_report = sv.analyze(pd.read_csv("titanic.csv"))
#Saving results to HTML file
sweet_report.show_html('sweet_report.html')
The report generated by the Sweetviz library includes an overall summary of the dataset, correlations, and associations for categorical and numerical features.
4. AutoViz
The Autoviz package can automatically visualize datasets of any size with one line of code and automatically generate reports in HTML, Bokeh, etc. Users can interact with the HTML reports generated by AutoViz.

python
import pandas as pd
from autoviz.AutoViz_Class import AutoViz_Class
#EDA using Autoviz
autoviz = AutoViz_Class().AutoViz('train.csv')
5. Dataprep
Dataprep is an open-source Python package for analyzing, preparing, and processing data. DataPrep is built on Pandas and Dask DataFrames, making it easy to integrate with other Python libraries. DataPrep is the fastest among these 10 packages; it can generate reports for Pandas/Dask DataFrames in seconds.
python
from dataprep.datasets import load_dataset
from dataprep.eda import create_report
df = load_dataset("titanic.csv")
create_report(df).show_browser()
6. KLib
Klib is a Python library for importing, cleaning, analyzing, and preprocessing data.
python
import klib
import pandas as pd
df = pd.read_csv('DATASET.csv')
klib.missingval_plot(df)
klib.corr_plot(df_cleaned, annot=False)
klib.dist_plot(df_cleaned['Win_Prob'])
klib.cat_plot(df, figsize=(50,15))
Although Klib provides many analysis functions, it requires manually writing code for each analysis, making it semi-automated. However, it is very convenient for more customized analysis.
7. Dabl
Dabl focuses less on individual column statistics and more on providing a quick overview through visualizations, as well as convenient machine learning preprocessing and model search.
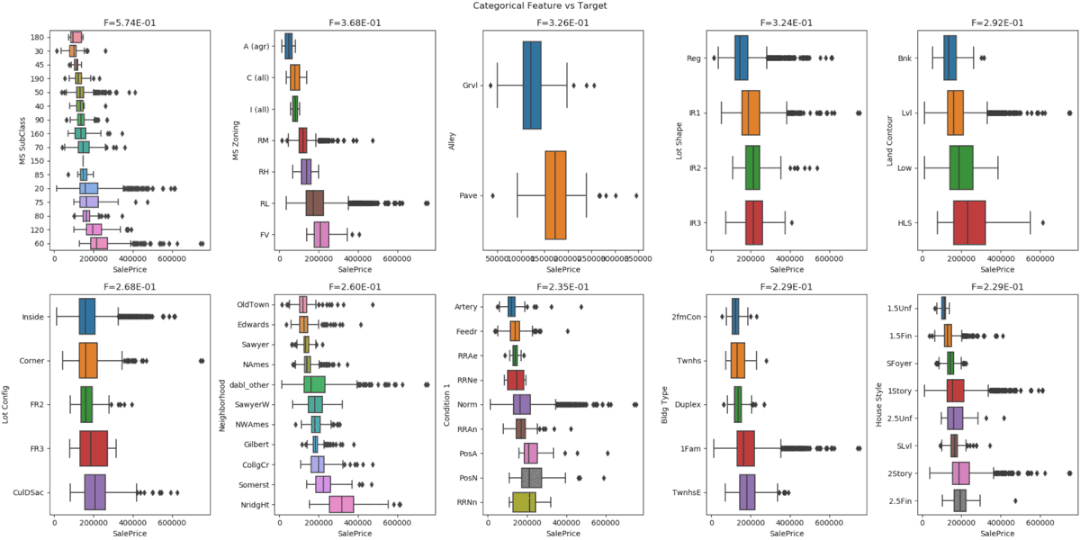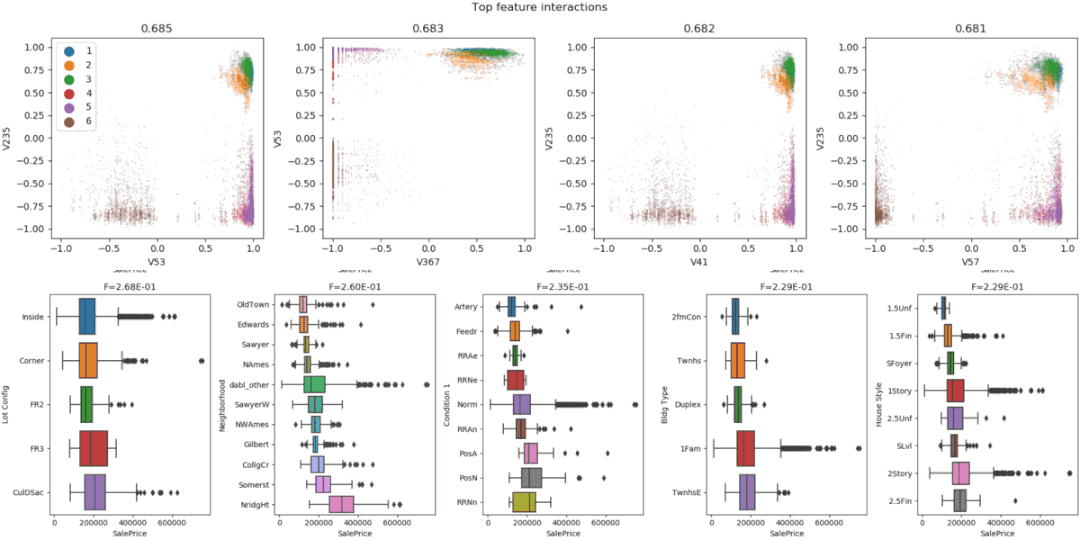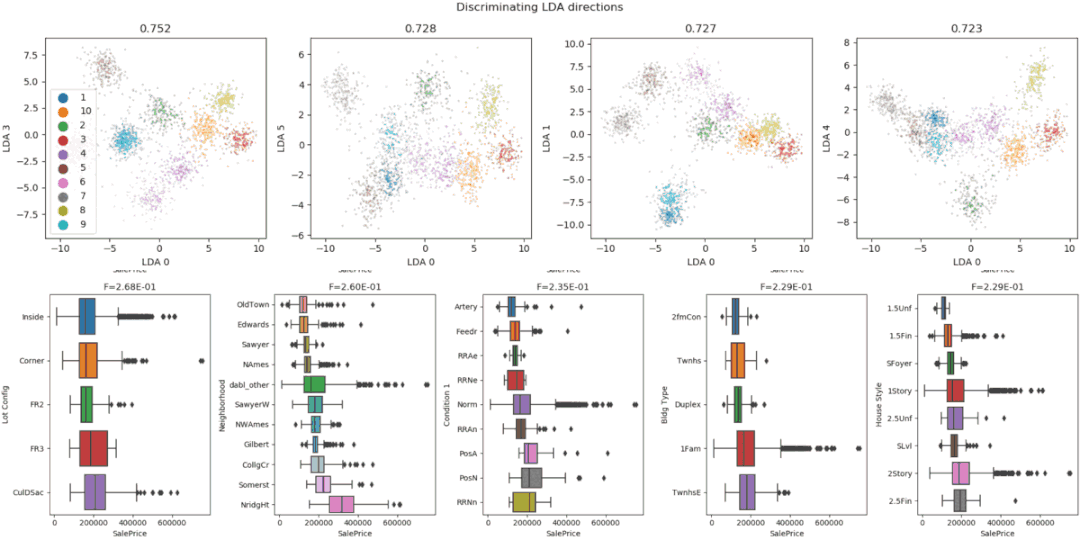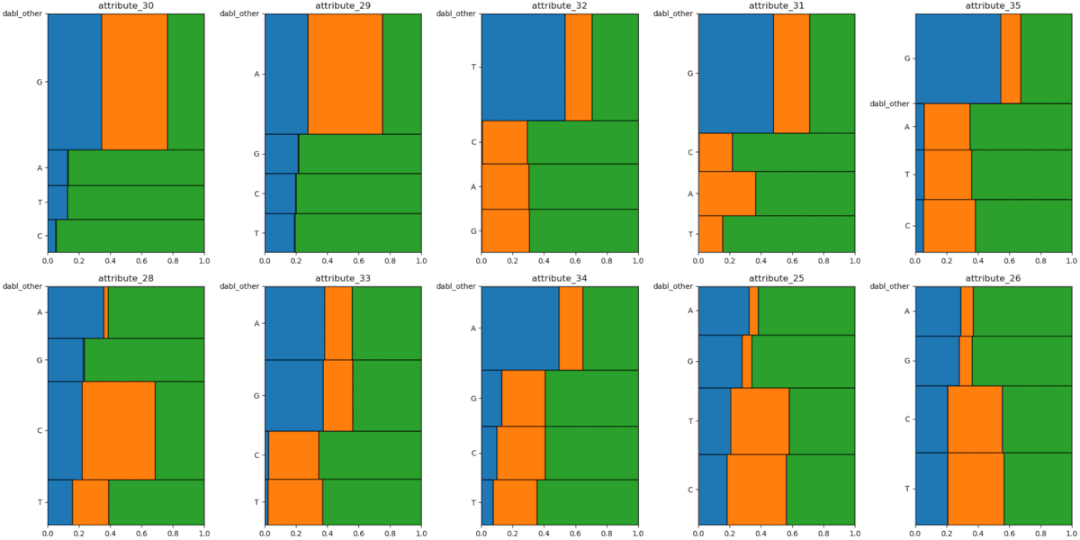
The plot() function in dabl enables visualization by creating various plots, including:
- Target distribution
- Scatter plots
- Linear Discriminant Analysis
python
import pandas as pd
import dabl
df = pd.read_csv("titanic.csv")
dabl.plot(df, target_col="Survived")
8. Speedml
SpeedML is a Python package for rapidly starting machine learning pipelines. SpeedML integrates several common ML packages, including Pandas, Numpy, Sklearn, Xgboost, and Matplotlib, so it offers more than just automated EDA. According to SpeedML, it enables iterative development and reduces coding time by 70%.
python
from speedml import Speedml
sml = Speedml('../input/train.csv', '../input/test.csv',
target = 'Survived', uid = 'PassengerId')
sml.train.head()
sml.plot.correlate()
sml.plot.distribute()
sml.plot.ordinal('Parch')
sml.plot.ordinal('SibSp')
sml.plot.continuous('Age')
9. DataTile
DataTile (formerly known as Pandas-Summary) is an open-source Python package for managing, summarizing, and visualizing data. DataTile is essentially an extension of the PANDAS DataFrame describe() function.
python
import pandas as pd
from datatile.summary.df import DataFrameSummary
df = pd.read_csv('titanic.csv')
dfs = DataFrameSummary(df)
dfs.summary()
10. edaviz
edaviz was a Python library for data exploration and visualization within Jupyter Notebook and Jupyter Lab. It was very useful but was later acquired by Databricks and integrated into bamboolib. Therefore, we will only give a brief demonstration here.
Summary
In this article, we introduced 10 Python packages for automated exploratory data analysis. These packages can generate data summaries and visualizations with just a few lines of Python code, saving us a significant amount of time through automation.
Dataprep is my most commonly used EDA package. AutoViz and D-Tale are also excellent choices. If you need customized analysis, you can use Klib. SpeedML integrates many features, so using it solely for EDA isn’t particularly ideal. You can choose other packages based on personal preference; they are all quite useful. Finally, edaviz is no longer recommended as it is no longer open source.




